Research funders are placing increasing emphasis on ensuring that participants in funded projects not only publish their results but also make the research data underlying those results accessible. Editors of scientific journals are likewise increasingly expecting authors, across more and more disciplines, to not only reference the data cited in their articles but also make those data discoverable and accessible.
In the scientific community, there is growing acceptance of the principle that research data—while respecting relevant legal and ethical regulations and taking researchers' interests into account—should be made as open and accessible as possible. In other words, data management should be "as open as possible, as closed as necessary."
For most research grant applications—if research data will be generated during the project—it is already a requirement to fill out a data management plan template provided by the funder, or to submit a brief description of the planned data management. If the project is funded, a more detailed plan must then be developed.
The "Guide to Managing Research Data":
- Provides support for planning the management of research data and preparing the corresponding data management plan;
- Outlines the latest trends and expectations related to research data;
- Includes recommendations and suggestions with the intention of supporting research and researchers.
These recommendations and suggestions can be integrated into research workflows at different rates depending on the scientific field.
Scientific Replication Crisis
A fundamental requirement of modern science, falsifiability, is a crucial component of the reproducibility of scientific measurements and, therefore, their reliability. Today, scientific practice worldwide places great emphasis (for example, through incentive systems) on producing new results. This often sidelines the (re)verification of existing scientific results and the assurance of the reliability of scientific research. In the 2010s, news of the re-examination of the results and circumstances of several well-known scientific experiments made headlines in the global press. This generated widespread doubt about the public perception of science and affected scientific discourse in general. The so-called scientific replication crisis[1] has brought new attention to the planned conditions under which research data are generated, their secure, long-term storage and publication, and the importance of open science initiatives.
- Research Data
-
Research data are factual information created, recorded, accepted, and preserved by the scientific community that support the credibility of research results.
Based on how they are generated, research data may arise from:
- Observation-based methods;
- Experiments;
- Simulation processes;
- The use of existing data sources (through collection, selection, interpretation, and processing).
Classified by their level of processing, research data can be:
- Raw or primary data (e.g., data obtained directly from measurement or collection);
- Processed or secondary data (derived from primary data after being processed by the researcher, e.g., recoded, combined, categorized, or used in calculations).
Based on their format, research data can be:
- Digitally generated data;
- Data not originally digital but later digitized; and
- Data neither digitally generated nor digitized (e.g., handwritten notes, field journals).
Examples of research data:
- Spreadsheets
- Results of measurements, applications, simulations, and data files created from them
- Photographs, films, slides
- Drawings
- Audio and video recordings, and their transcriptions
- Protein or gene sequences
- Data files created from questionnaire survey responses
- Interview recordings and transcripts
- Objects acquired and/or produced during the research process – both digital and non-digital
- Text corpora
Research Documentation
Research documentation refers to the collection of files generated alongside research data, closely related to them, and to be handled and stored together with them.
Examples of research documentation:
- Research plans
- Notes, outlines
- Descriptions of methods and workflows
- Questionnaires, interview guides, codebooks
- Models, algorithms, codes, scripts, software developed for research
- Laboratory notes, journals, memos, protocols
- Research data life cycle
-
The life cycle of research data can be divided into seven main stages:
- Planning data management
- Data collection and creation
- Data processing
- Data analysis
- Data storage
- Data sharing
- Data reuse
Research data life cycle
Kép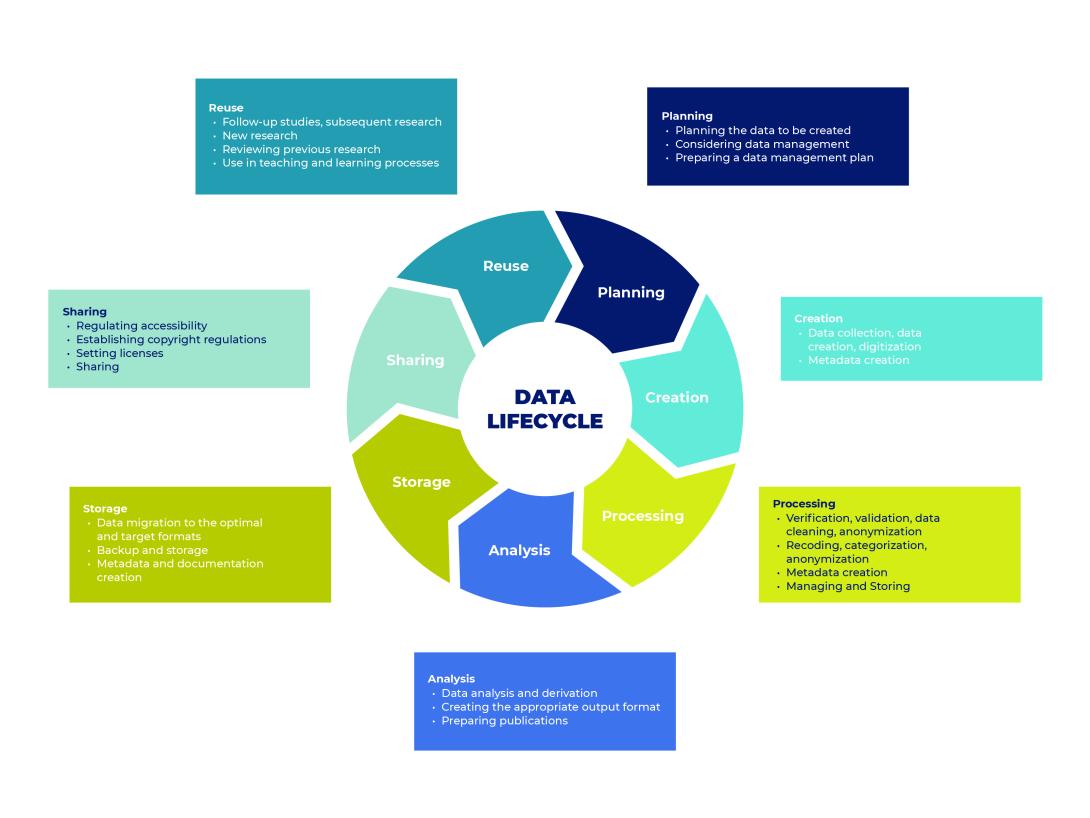
Source: https://rdmkit.elixir-europe.org/data_life_cycle, Hungarian translation and visualizatioby a HUN-REN ARP project - Research Data Management
-
Research data management encompasses all decisions and activities related to research data from the planning phase of a research project to long-term storage. It includes how, where, and under what conditions research data is collected, processed, stored, shared with others, archived (stored long-term), made accessible, and reused. Thoughtful research data management supports and optimizes the research process.
FAIR Research Data Management
The acronym FAIR stands for Findable, Accessible, Interoperable, and Reusable. These principles were introduced in 2016 by a consortium of researchers and research institutions in the article The FAIR Guiding Principles for scientific data management and stewardship,[1] published in Scientific Data.
The primary goal of the FAIR principles is to support the reuse of scientific data. As the speed, volume, and complexity of data creation in research increase, researchers increasingly rely on machine support in handling data. Therefore, data management must enable computer systems to find, access, work with, and reuse various research data with minimal or no human intervention. According to the original concept, FAIR data management is thus intended primarily to facilitate machine, rather than human (researcher) access to data.
Kép
Source: HUN-REN ARP Project FAIR data management is not the same as Open Data: research data does not necessarily have to be openly accessible to everyone to be considered FAIR. The principles of findability and accessibility mainly apply to metadata describing the research data, as metadata enables data to enter the scientific ecosystem.
[1] Wilkinson, M., Dumontier, M., Aalbersberg, I. et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci Data 3, 160018 (2016). https://doi.org/10.1038/sdata.2016.18
Open Science and Open Data
Open Science is the result of a 50-year evolution in how scientific research is shared. The Open Science movement promotes collaboration, transparency, accessibility, and usability of scientific research.
The rapid development of digital technologies and the explosive growth of the Internet first enabled wide access to scientific outputs (publications, talks), and later the sharing of research data, intermediate results, and accumulated knowledge generated in earlier phases of the research process.
The goal of Open Science is to make the knowledge generated during scientific research accessible as early as possible in the research process, as widely as possible, ideally freely and openly.
One of the movement’s key insights is that open research results and open data can greatly enhance the visibility and overall impact of research.
The Open Science movement encompasses both publications and research data. Its key components are Open Access and Open Data. Open Access refers to any scientific information, data, or knowledge that is digitally, freely, and legally accessible online, allowing unrestricted and lawful reuse. While "Open Access" primarily refers to publications and studies, "Open Data" is used to signal the openness, free and legal accessibility of research data.
Principles of Open Science
- “As open as possible, as closed as necessary”, and
- "Publish earlier and release more”
The first emphasizes a commitment to open access while calling for careful attention to data and information that require protection. The second encourages sharing knowledge as early as possible in the research process.
One of the safest and most effective ways to make research data openly and freely accessible is through Open Access Repositories. These repositories provide free and open storage and download opportunities for researchers to share their research data or find and reuse the data of others.
Open Data and FAIR
Open research data and FAIR data do not always overlap. A dataset can be FAIR (for example, its metadata is accessible in a FAIR-compliant way) but not open (the data itself may have restricted access).
One of the goals of the Open Science movement is to bring Open Data and FAIR data closer together by increasing the overlap and expanding the intersection of the two.
The Relationship Between FAIR and Openly Managed Research Data
Kép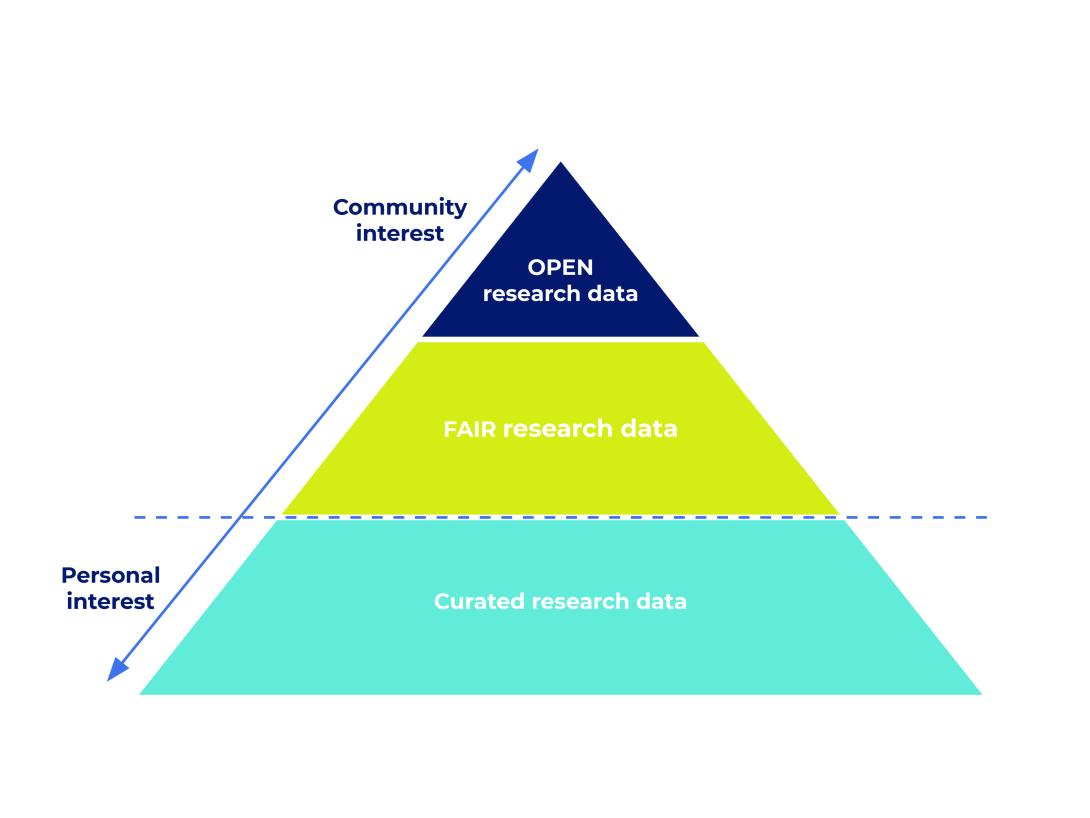
Source: https://www.dcc.ac.uk/, https://www.slideshare.net/sjDCC/open-fair-data-and-rdm, Hingarian translation and visualization by HUN-REN ARP Project
- Non-digital research data
-
Not all research data is inherently digital. Many researchers keep handwritten logs or field journals, and some materials or documents that qualify as research data—due to their origin, nature, or the nature of the research—are produced or exist primarily or exclusively in non-digital form. Examples include paper questionnaires, paintings, archaeological finds, minerals, or even tissue derived from living organisms.
Digitization of non-digital research data
In the case of several types of non-digital research data, digitization is possible, offering the following advantages:
- sharing and publishing the data becomes simpler and cheaper;
- digital data management is generally more cost-effective;
- the data becomes more easily accessible and searchable;
- access rights and user groups can be clearly defined, increasing data security;
- materials and documents not preserved digitally are more vulnerable to decay and degradation—digital long-term preservation supports their survival and accessibility in proper quality;
- in the event of natural disasters or even human error, research data, objects, or documents available only in non-digital format can be damaged or destroyed—digitization in such cases serves a crucial preservation role.
Metadata for non-digital research data
Digitizing non-digital research data is generally a resource-intensive process. If a research institution has no or only limited capacity (e.g. due to lack of staff or equipment) for digitization, making the metadata of the research data accessible can be a way to increase their visibility and accessibility.
When providing metadata for non-digital data, it is important to record:
- the exact (physical) storage location of the data;
- the conditions and methods of access;
- access rights;
- and as much other relevant information as possible for potential interested researchers, either in the form of metadata or brief descriptions.
- Metadata
-
Metadata serve to identify research data as completely as possible. In long-term data storage (in repositories), metadata stored together with the research data support the searchability and findability of the data. Metadata can be generated manually, automatically by an algorithm or measuring instrument, or through a combination of these.
Metadata represent the set of facts and information about research data—data about data. The most general metadata include the name of the data, its creator, source, date and method of creation, but metadata also include origin, temporal references, geographic location, access conditions, or terms of use.
The concept of metadata can be easily understood through the following concrete example. Digital cameras automatically generate and store certain information about the digital image—that is, the digital file—at the moment of capture. Such information may include:
- the time the photo was taken;
- the resolution of the image;
- the file type;
- the file size.
These are metadata—specifically, automatically generated metadata, which primarily carry technical information about the digital document.
Modern cameras, when properly configured, also store the exact location where the picture was taken. In addition, users can provide further information themselves; for instance, in the case of a photo, one can specify the names of the objects depicted or the event during which the picture was taken. This creates additional metadata, which no longer provide technical but descriptive information about the digital image. These descriptive data support the future reuse and retrievability of the image.
Metadata can therefore be assigned automatically or manually to any digital file, including digitally available research data. Digitally generated metadata (such as the precise minute or second a photo was taken in the camera example) not only support external users in searching for and validating research data, but also provide researchers with highly accurate and important information regarding certain aspects of their research.
Metadata schema
Both digital documents (e.g., research data) and the digital collections containing them (e.g., data packages) can vary greatly in form and may differ significantly in many aspects and levels. Consequently, the metadata that describe them can also be very diverse, which has made it necessary to develop unified standards for metadata usage—to ensure interoperability and facilitate easier searching. This is how different metadata schemas were created, which greatly contribute to the ease of search and actual discoverability of research data and other digital information sources.
A metadata schema is a defined set of metadata elements (element set) and the associated rules.
One of the most widespread metadata schemas is the Dublin Core. The Dublin Core element set contains descriptive metadata and is general and applicable across all scientific disciplines, making it widely used. It is characterized by simplicity and flexibility; the schema is well-structured and easy to understand.
The name’s first part refers to the workshop location where it was developed in 1995. In Dublin, Ohio, the OCLC/NCSA Metadata Workshop brought together a group of experts with the goal of creating a metadata element set that would be sufficient and appropriate for describing digital information resources. The second part (Core) refers to the idea that the element set is a foundational core that can be expanded.
Its element set has since become an ISO standard; in Hungary, it was issued in 2004 under the title „MSZ ISO 15836 Információ és dokumentáció. A Dublin Core metaadat elemkészlete” (“MSZ ISO 15836 Information and documentation – The Dublin Core metadata element set”).
The 15 core elements of Dublin Core adapted to research data
Kép
Source: HUN-REN ARP Project Different scientific disciplines may use specifically developed metadata standards tailored to the characteristics of the research data typically generated in that field. In the absence of an appropriate standard, individual institutions, projects, or research groups may create their own. When developing a new schema, it is important to ensure that it adheres to the FAIR principles of standardization—that is, it should be consistent and interoperable within the given scientific domain. Currently, several international organizations (EOSC, RDA, GOFAIR) are working on creating frameworks that provide guidance for the development of metadata standards.
Individual repositories often have their own metadata schemas; however, these are generally interoperable. The metadata schema used to describe research data, along with the element set listed within it, is typically suggested by data repositories during the upload process. The repository system attaches the provided metadata to the research data, which helps ensure that the data are properly searchable.
- Data Management Plan (DMP)
-
The written, recorded form of research data management is the Data Management Plan. The Data Management Plan, or DMP, is a brief summary document—typically a few pages long—where the research lead or data steward outlines the research data and how they will be managed, including decisions and activities related to data handling. The goal is to ensure the lawful (according to the defined standards), ethical collection and management of the data, as well as their secure storage during the research and after its conclusion.
Creating a DMP is in the interest of the researcher or research group, but it is increasingly common for funders and grant-awarding organizations to request the first (initial) version of the plan already at the submission of the research proposal. This promotes thoughtful data management, the creation of accessible, sustainable, and reusable data, and the effective application of the principles of knowledge sharing and open science.
Planning research data management and preparing a DMP:
- supports the research itself;
- helps with the conscious management, long-term preservation, and future reuse of research data;
- contributes to the prevention of data loss;
- and, if there are institutional or funding requirements, ensures compliance.
The DMP is a structured document, mostly written in outline form and often arranged in a tabular format. Its depth and detail depend on the researcher’s decisions and/or the requirements of the funder, grant agency, or research institution. It generally includes the following main sections, which can be supplemented with additional relevant data management information:
- Basic information
- Title of the research
- Host/affiliated institution
- Funder of the research
- Duration of the research
- Short description of the research
- Name(s) of participating researcher(s)
- Name of the data steward
- Research data
- Method of data collection or creation
- Type and characteristics of the resulting data
- Method of data processing
- Metadata and metadata schema specification and description
- Data storage and Sharing
- Data storage and protection during the research
- Data sharing, access options, and permissions during the research
- Data storage and protection after the research ends
- Data sharing, access options, and permissions after the research ends
- Scope of data to be destroyed
- Scope of data and documentation to be deposited in repositories
- Scope of research data and documentation to be openly/partially/not accessible after the research
- Location of data access
- Persistent (unique permanent) identifiers
- Ethical and Legal Compliance
- Scope, Protection, and Handling of Personal, Sensitive, and Confidential Data Covered by the GDPR
- Costs and Resources
- Costs related to data management
- Agreements with funders, data providers, or research partners
- Other Field-Specific Information
In some cases, for grants or contracts, the funder or client may provide a DMP template or a detailed guide (e.g., OTKA Data Management Plan, Horizon 2020 Data Management Plan Template). Research institutions may also develop their own templates or guides. In the absence of such resources, the researcher may create the DMP independently, ideally with the help of a data steward or data specialist.
The DMP is a flexible document that may be revised over the course of the research. It is recommended to review it regularly, update it if necessary, and record changes in new versions with version numbers.
Useful links for creating a DMP:
- Zenodo Checklist for Data Management Plan
- Science Europe Guidance Document
- Zenodo Practical Guide to the International Alignment of Research Data Management - Extended Edition
- SND Checklist for Data Management Plan
Online tools for creating a Data Management Plan:
- Data Storage
-
To minimize the risk of data damage or loss, it is important to ensure the secure storage of data generated during each phase of the research. Therefore, research data should always be backed up, preferably in multiple different locations. It is recommended to follow the “here-near-far” principle, meaning one copy should be on the researcher’s own computer, another on a local data storage device (e.g., external hard drive, institutional server), and a third on a remote server (e.g., a repository).
When storing research data, it is essential to prevent unauthorized access, data manipulation, or misuse, paying particular attention to the secure storage of sensitive data, and ensuring compliance with relevant contracts, agreements, declarations, regulations, and ethical standards whenever access is granted.
When selecting the method or tool for data storage, the following factors should be considered:
- How long the data needs or is planned to be stored;
- The volume of the data;
- With whom, how many people, and in what way the data should be shared;
- Whether any sensitive data is generated;
- What resources are available;
- Whether there are any institutional or other requirements related to data storage.
Common solutions for storing research data include:
- Personal local storage solutions (e.g., personal computer, external hard drive)
- Institutional local storage solutions (e.g., institutional computer, institutional server, external hard drive)
- Personal cloud-based storage services (e.g., OneDrive)
- Institutional cloud-based storage services (e.g., institutional cloud)
- Git-type repositories
- Personal website
- Institutional/project website
- Databases
- Data repositories
There are two types of data storage:
- Data storage during research
- Long-term data storage after the research has concluded (archiving)
The method and location of both types of data storage should be carefully planned, weighing the above factors and options. It is possible to store data in repositories during the research, but repositories are primarily intended for long-term storage after the project ends. Currently, data repository storage is the most secure method for long-term preservation of research data.
File Structure and File Naming
Folders and data files should be organized and named according to the logic of the given research in a way that makes them understandable to others. All team members working on the project should follow the same file naming rules. The method used to create file and folder structures and naming conventions should be included in the data management plan.
Useful types of information that may be included in file names to help distinguish them:
- Title or acronym of the research/project/experiment
- Location / spatial coordinates
- Researcher’s name or initials
- Date of creation
- Type of data
- Version number
Example of a File Structure and File Naming System
Kép
Source: https://www.wur.nl/en/Value-Creation-Cooperation/Collaborating-with-WUR-1/Organising-files-and-folders.htm / Translation and visualization by HUN-REN ARP Project - Publishing and Sharing Research Data
-
Research data should be made publicly available after the completion of the research (or even during the research period) following the principle of “as open as possible, as closed as necessary.” It is important that publication aligns with institutional, funder, and publisher requirements, the practices of the relevant academic discipline, and the researcher’s own needs, while also adhering to the FAIR principles. The aim is to ensure visibility, accessibility, and long-term preservation.
Possible methods of publication include:
- In a general, subject-specific, or institutional data repository
- As supplementary material alongside a journal article
- In the form of a data paper in a data journal
- In a public database
When publishing research data, it is necessary to consider the declarations, permissions, consents, and contracts previously made, as well as the regulations and recommendations of the selected publication venue.
The nature of the research data must also be taken into account when determining whether and how to share it. Careful consideration is needed in the case of:
- Research data with commercial potential
- Research data under classification or confidentiality restrictions
- Sensitive research data, such as:
- Personal data
- Confidential data (e.g., patient information)
- Data under other types of protection (e.g., environmental protection)
- Third-party data governed by contractual agreements
- Research data that could endanger national or international strategy, autonomy, or security
- Data Repository
-
Research data can be stored long-term in various ways. The most secure location for archiving is a data repository, which is a complex infrastructure designed for the safe and long-term storage, archiving, publication, sharing, and access of digital research data.
Research data published in a repository can be assigned different access permissions. The researcher must ensure that the most appropriate access level is set for their data. Access can be:
- Open – in this case, the research data is freely accessible without restriction, or
- Restricted – in this case, the data is only available to those who request access and are authorized by a designated person (e.g., the data steward or principal investigator of the project).
Why is it beneficial to store research data in a data repository?
The primary goal of depositing data in a repository is to ensure its long-term storage and accessibility.
Benefits of using a data repository:
- Secure archiving
- Safe, long-term storage
- Secure data management
- Accessibility
- Secure (open or restricted) data sharing
- Visibility
- Searchability
- Accessibility (especially important for research funded by public money)
- Data reusability
- Verifiability
- Ensuring research data can be verified
- Reliable version control (documenting the extension, replacement, or modification of data)
- Compliance with grant, institutional, and journal requirements
What should we deposit?
Placing research data in a data repository primarily concerns the research data collected, measured, generated, used, and derived during the course of research. However, research data alone is often not interpretable or not sufficiently interpretable, so it is equally important to deposit the information and sources that supplement, explain, place the data in context, and ensure their discoverability in the repository.
The package to be deposited in the repository should include:
- research data
- research documentation
- research algorithm, software, model (if any)
- readme file
- metadata
To ensure that the research remains comprehensible, transparent, and reusable in the future, creating and attaching a readme file upon repository submission is strongly recommended. The readme file summarizes the context of the research and the most important information (a brief description of the research, background, methodology, content of the data package, file descriptions, etc.) so that the research data and documentation can still be understood and used by users (who were not involved in the research and do not know the researchers) even years or decades later. The readme file may be a structured or continuous text document and may be based on any description of the research (e.g., the research plan, project proposal).
Metadata is generally not provided in a separate file, but is entered through the data repository interface by filling out the fields presented during the data upload process.
Depositing research software
Research software refers to source code files, algorithms, scripts, computational workflows, and executable files created during or specifically for a research project. Software or software components used in research but not created specifically for that research (e.g., operating systems, commercial software, code/scripts/algorithms previously written by others) are not considered research software but rather software used in research.
Proper storage and publication of research software developed specifically for a study is essential for ensuring the research can later be understood and replicated.
Additional benefits of depositing research software may include:
- Citability: published research software can be included in a professional CV, enabling citation
- Contribution to the field: researchers in the field may find the methodology, code, or data useful
- Institutional continuity: in institutions with high staff turnover, making research data, documentation, and software available ensures that future team members can understand and replicate the research
- Helping our future selves: documenting research software and related workflows helps researchers themselves retrace steps. If the software needs to be retrieved after the research concludes (due to slow journal review or revisiting the work), careful preservation and accurate documentation can save significant time and effort.
How to deposit?
To ensure that research materials uploaded to a data repository remain readable and reusable in the future, the following preparatory steps are necessary:
- Select appropriate research data and materials; determine which files belong in a data package: carefully select data, documentation, and other materials that substantiate the results or are otherwise valuable for future use (not all files generated during research must be deposited)
- Anonymization: if the research materials contain personal, sensitive, or confidential data, anonymize or hash the data, protect them appropriately, restrict access, or refrain from depositing such data
- Data cleaning: if needed, clean and prepare data for reuse. For example:
- check that the A1 cell in a spreadsheet is the top-left cell of the table
- avoid embedded tables or charts within spreadsheets
- avoid merged cells in spreadsheets
- avoid color coding
- avoid special characters
- Thoughtful data labeling: use clear labels, descriptions, and explanations for research data in line with disciplinary standards to ensure interpretability. For example:
- use clear column headers in spreadsheets
- preferably use single-row headers
- provide a legend or key for each table
- Use appropriate file formats: if possible, use formats that are standard in the discipline, widely used, open-access, machine-readable, and not easily modifiable. The deposited file formats may differ from those used during the research.
- Use clear filenames: choose understandable, consistent, content-reflecting names for files.
- Develop a well-structured data and file organization: organize files and data clearly, aligned with disciplinary norms and research logic for future clarity
- Upload separate files: deposit tables as separate files, even if they belong together; deposit Excel sheets as individual tables when possible
- Version control: if multiple versions of a research dataset or documentation are deposited, clearly distinguish them to ensure traceability of changes
- Create a readme file: to ensure interpretability and context, a readme file should be included with the data
- Provide detailed metadata: ensure interpretability and searchability using a metadata schema accepted in the discipline and repository
- Define rights, ethics, and licenses: only deposit data and documentation that meet legal and ethical standards; set access levels to ensure compliance
What file formats should we use for depositing?
A key issue in long-term storage is the file format of the research data deposited in the repository. International practice offers various recommendations, but the basic principle is consistent: data should be preserved and shared in formats that can be opened with open-source programs and ensure long-term accessibility.
The file formats used during research and those preserved afterward do not necessarily have to match. Editable formats used during research or files generated by special instruments or algorithms may be worth converting into more durable formats at the end of the project. If possible, consider sharing the data in multiple formats.
Recommended, acceptable and not recommended file formats
Kép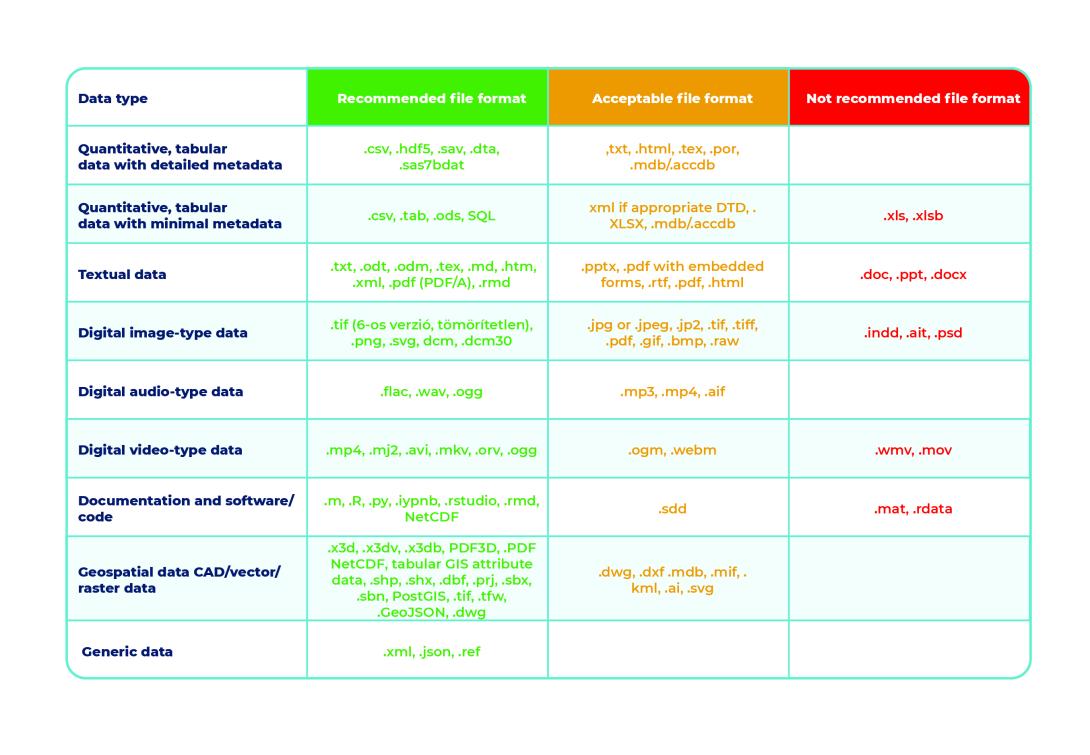
Source: https://openscience.hu/f-a-i-r-kutatasi-adatkezeles/ and https://ukdataservice.ac.uk/learning-hub/research-data-management/format-your-data/recommended-formats/
Where should we deposit?
Choosing the right data repository should consider both general and research-specific criteria.
In 2020, a research group developed general evaluation criteria under the TRUST Principles . The acronym stands for Transparency, Responsibility, User focus, Sustainability, and Technology.
According to the TRUST Principles, a trustworthy repository should:
- Transparency: have clear and publicly accessible service and data management policies
- Responsibility: ensure data authenticity and integrity and the reliability of repository services
- User focus: provide data management aligned with user needs
- Sustainability: guarantee long-term data management and storage
- Technology: provide a secure, reliable, and permanent service infrastructure
Other important general criteria for selecting a repository may include:
- Security: ensure proper protection of data
- PID provision: assign a persistent (unique) identifier (e.g., DOI) to deposited data packages
- Searchability: offer a metadata schema that supports data discoverability
- Openness: repository and metadata should be publicly accessible
- Customizability: allow setting of access rights to data individually
- FAIR: ensure data management complies with FAIR principles
Additional considerations may include:
- Acceptance in the field: meet the requirements of the journal/funder/research institution
- Free access: uploading and usage should be free (with proper affiliation)
- Helpdesk: supported by a responsive and reliable support team
Some cases require a specific data repository for storing research data. For example, if a journal only accepts data linked to its own repository, or if data from a specific instrument can only be stored in a repository operated by the institution running the instrument.
A fundamental principle is to choose a disciplinary or institutional repository when available. If none is available, select a general-purpose repository. It is recommended that data produced in Hungary be uploaded to a Hungarian repository (especially for publicly funded research).
Institutional data repositories at HUN-REN
A HUN-REN kutatói számára jelenleg rendelkezésre álló adatrepozitóriumok
- a Kutatási Dokumentációs Központ (KDK) repozitóriuma, valamint
- a HUN-REN Adatrepozitórium Platform (HUN-REN ARP) adatrepozitórium, amely a korábbi Concorda adatrepozitórium továbbfejlesztett és kibővített változata.
A KDK repozitóriumában a Társadalomtudományi Kutatóközpont (TK) négy intézetének kvalitatív és kvantitatív módszerekkel készült kutatásainak kutatási adatai és dokumentációja (interjúk felvételei, leiratai, vezérfonalai; kérdőíves felmérések kérdőívei, módszertani leírásai, adatbázisai; terepnaplók, megfigyelések jegyzőkönyvei stb.) érhetők el, különböző (szöveg, kép, videó stb.) formátumokban. A metaadatok minden esetben nyíltan hozzáférhetők.
A HUN-REN ARP Adatrepozitórium a HUN-REN által fenntartott, a TK, a SZTAKI és a Wigner kutatóintézetek közreműködésében fejlesztett intézményi adatrepozitórium. Az adatrepozitórium minden HUN-REN kutatóhely számára elérhető, minden tudományterület adatait tárolni képes infrastruktúra. Az ARP repozitóriuma Harvard Dataverse alapú, azt azonban további funkciókkal kiegészítő többkomponensű rendszer.
A HUN-REN ARP a HUN-REN által fenntartott, a TK, a SZTAKI és a Wigner kutatóintézetek közreműködésében fejlesztett intézményi adatrepozitórium. Az adatrepozitórium minden HUN-REN kutatóhely számára elérhető, minden tudományterület adatait tárolni képes infrastruktúra. Az ARP repozitóriuma Harvard Dataverse alapú, azt azonban további funkciókkal kiegészítő többkomponensű rendszer.
- Egyedi, állandó azonosító (persistent identifier, PID)
-
Egy megbízható adatrepozitórium képes a benne őrzött digitális objektumok (adatok, adatcsomagok) fellelhetőségét és azonosíthatóságát biztosítani. Ennek a képességnek fontos komponense, hogy a repozitált digitális objektumokhoz perzisztens azonosítók kapcsolódjanak, azok az objektumok metaadatai között szerepeljenek. A perzisztens (állandó) azonosítók a digitális objektumok hosszú távú, globális és egyértelmű azonosítására szolgálnak, általában számokból és betűkből álló, linkkel ellátott kódként generálják azokat. A perzisztens azonosítók fontos feladata, hogy konzisztens módon biztosítsák az adatok elérését, azaz abban az esetben is, ha azok tárolási helye megváltozik. A perzisztens azonosítók így az adatrepozitóriumtól független entitások kell hogy legyenek. A leggyakoribb perzisztens azonosítók a DOI, az ARK, a Handle, az ORCID vagy a ROR. Az előbbiek adatok, adatcsomagok, az utóbbi kettő kutatók (szerzők), és (kutatással foglalkozó) intézmények azonosítására szolgálnak.
A DOI (Digital Object Identifier) a legelterjedtebben alkalmazott azonosító mind a tudományos publikációk, mind a kutatási adatok esetében. Előnye az elterjedtségen, szabványosságon túl a központi metaadattár (az egyes DOI ügynökségek, mint a DataCite és a CrossRef külön adattárat működtetnek), az adatáramlást elősegítő megoldások léte és terjedése (CrossRef - ORCID kapcsolat) és a scientometriai beágyazódás (DOI aratás a cikkekből).
A szabványos azonosítókon belül léteznek lokális, helyi adatbázisokkal kiszolgálhatók, ilyen például az ARK (Archival Resource Key). Elterjedt perzisztens azonosító továbbá a Handle, amely nem kereskedelmi alapon fejlesztett decentralizált azonosítórendszer, globális (vagy lokális) bővebb metaadattára azonban nincsen.
- Felhasználói engedélyek (licencek)
-
A kutatási adatok közzétételekor el kell dönteni, hogy a közzétett adatokkal mások mit kezdhetnek, hogyan használhatják fel azokat. Ennek meghatározására szolgálnak a licencek. A legelterjedtebb Creative Commons (CC) licencek kutatási adatok esetében is jól használhatók, mivel ismertek, átláthatók és a keresőmotorok számára is olvashatók.
A licencek tulajdonképpen engedélyekként értelmezhetők bizonyos feltételek teljesülése esetén.
Mielőtt licencet választanánk adataink megosztásához, érdemes utánajárni, hogy a kutatási adatok tulajdonosa és/vagy a kutatás finanszírozója tett-e bármilyen megkötést e tekintetben (akár a finanszírozáshoz, akár a helyi irányelvekhez kapcsolódóan). A Creative Commons licencek hét különböző típusát különböztetjük meg, amelyek két jog és négy korlátozó feltétel variációiból állnak össze. Utóbbiak a:
KépMegosztási jog[2] KépFeldolgozási jog[3] Kép„Hivatkozd!” feltétel (BY)[3] Kép„Ne üzletelj vele!” feltétel (NC)[4] Kép„Ne változtasd!” feltétel (ND)[5] Kép„Ugyanígy oszd meg!” feltétel (SA)[7] A jogok és feltételek részletesen a következőket takarják:
Megosztási jog: lehetőséget nyújt arra, hogy a licencelt mű szabadon másolható, terjeszthető, bemutatható és előadható legyen.
Feldolgozási jog: lehetőséget nyújt arra, hogy a licencelt mű alapján származékos művek (feldolgozások) legyenek létrehozhatók.
„Hivatkozd!” feltétel: a licencet kibocsátót (azt kibocsátani joggal rendelkezőt) fel kell tüntetni az adatok használatakor, megosztásakor, egyéb jellegű megjelenítésekor.
„Ne üzletelj vele!” feltétel: célja, hogy megakadályozza az adatokkal való üzleti jellegű visszaélést; sok esetben ún. duális rendszerben kerül használatra, az üzleti felhasználást lehetővé tévő, fizetős licenccel párban.
„Ne változtasd!” feltétel: megengedi egy anyag másolását és terjesztését, de tiltja annak mindennemű változtatását, adaptálását, átformálását vagy lefordítását, vagyis csak az eredeti verzió használható és terjeszthető. Röviden: nem engedélyezett az eredeti anyag felhasználása más anyagok vagy adaptációk létrehozásához.
„Ugyanígy oszd meg!” feltétel: az adatokból származó, azokat felhasználó új munkák megjelentetésekor azokat a forrásadatokhoz tartozó licencekkel azonos licencekkel kell ellátni.
Creative Commons licencek
Kép
Forrás: https://hu.wikipedia.org/wiki/Creative_Commons, magyarra fordítás, grafikai megjelenítés a HUN-REN ARP-projekt keretében, https://creativecommons.org/about/cclicenses/ A Creative Commons-nak van magyarul is elérhető licencválasztó felülete, amely a fenti döntések meghozatalát követően megmutatja, melyik licenc illik leginkább az adott kutatáshoz.
Részletesebb útmutatás (angol nyelven) a Digital Curation Centre oldalán található.
[1] To share (right)
[2] To remix (right)
[3] Attribution requirement (BY)
[4] Non-commercial requirement (NC)
[5] No derivative works requirement (ND)
[6] Share alike requirement (SA) - Etikai szempontok, adatvédelem
-
Szenzitív adat minden személyes adat, valamint minden olyan további adat, amely egyének, fajok, tárgyak vagy helyszínek azonosítására alkalmas, és amelynek nyilvánosságra kerülésével fennáll a diszkrimináció, a károkozás vagy a nem kívánt figyelem kockázata.
Személyes adat minden olyan információ (például: név, lakcím, igazolvány szám, testi, szellemi, gazdasági, kulturális, származásbeli, politikai, vallási vagy világnézeti tényező, egészségügyi adat vagy szexuális életre vagy irányultságra vonatkozó információ), amely alapján valamely természetes személy azonosítható.
Egyes kutatások során szenzitív (személyes, bizalmas, titkos vagy egyéb módon érzékeny) adatok is keletkezhetnek, amelyeket kiemelt gondossággal kell kezelni a kutatás alatti tárolási mód kiválasztásakor, az adatok más kutatókkal vagy egyéb személyekkel való megosztásának esetén, és a hosszú távú megőrzés kialakításakor is. A szenzitív, különösen a személyes adatok kezelésének módját a kutatásiadat-kezelési tervben külön részletesen meg kell adni, a hozzájuk kapcsolódó kezelési (pl. az érintettektől) és egyéb (pl. etikai) engedélyeket be kell szerezni.
A kutatás során különös figyelmet kell fordítani arra, hogy a személyes adatok kezelése összhangban legyen a GDPR rendelkezéseivel.
Etikai és adatvédelmi szempontok minden olyan kutatás esetében felmerülnek, ahol személyek a kutatás alanyai. Szenzitív adatok továbbá egyéb területen is keletkezhetnek, ilyen lehet például egy veszélyeztetett faj előfordulási helyét vizsgáló, vagy egy üzleti érdekeket, titkos információkat tartalmazó kutatás, de más speciális területen vagy kutatásban is keletkezhetnek hasonló adatok.
Minden kutatást a kutatásetikai és az adatvédelmi szempontok figyelembevételével kell elvégezni. Amennyiben szükséges, a kutatás előkészítésekor vagy a kutatás alatt be kell szerezni az elvárt, kutatási adatokkal kapcsolatos kutatóhelyi és/vagy tudományterületi nyilatkozatokat, engedélyeket, valamint személyes adatokat is kezelő kutatás esetén a kutatás alanyainak nyilatkozatait. A bennük, valamint az egyéb, a kutatás előtt vagy során beszerzett engedélyekben, nyilatkozatokban, megállapodásokban és szerződésekben foglaltakat a kutatás során végig figyelembe kell venni, az érintett kutatási adatokat azoknak megfelelően kell kezelni.
A szenzitív adatok kezelésekor többek között az alábbi szempontokat kell körültekintően átgondolni és figyelembe venni:
- A kutatás előkészítése során:
- A kutatási terv elkészítése során végig kell gondolni és a kutatási tervben jelezni, hogy keletkeznek-e szenzitív adatok a kutatás folyamán
- A kutatás során törekedni kell arra, hogy csak feltétlenül szükséges személyes adatok legyenek rögzítve és tárolva
- Tájékoztató és beleegyező nyilatkozatban kell rögzíteni, hogy a kutatás hogyan biztosítja a különböző szakaszokban – beleértve az adatok megosztásának, újrafelhasználásának lehetőségét is – a szenzitív, különösen a személyes adatok védelmét
- Amennyiben a kutatás lezárulása után, hosszú távon is érdemes megőrizni és/vagy elérhetővé tenni egyes személyes adatokat, úgy a kutatás elején valamennyi, a kutatás személyes adattal érintett alanyától írásos beleegyezést kell kérni a szenzitív adatok tárolásához és/vagy nyilvánosságra hozatalához
- A kutatás során:
- Különös figyelmet kell fordítani a szenzitív, különösen a személyes adatok tárolására, a hozzáférés, megosztás meghatározására és módjára (pl. felületére)
- Kizárólag feltétlenül szükséges esetben, és a lehető legrövidebb ideig indokolt a személyes adatok kezelése és tárolása
- A kutatásban való részvételnek a résztvevők szabad akaratából kell történnie
- A kutatás lezárultát követően
- Ha kutatási szempontból már nem indokolt a személyes adatok megőrzése, gondoskodni kell azok biztonságos és teljes törléséről
- Ha a szenzitív, különösen a személyes adatok nem törölhetők, álnevesítéssel, anonimizálással csökkenthető az adatkezelés negatív következményeinek kockázata
- A GDPR szerint anonimizált adatok esetében nem kell alkalmazni a személyes adatok védelmére vonatkozó szabályokat
- A kutatási adatok repozitálásakor, szenzitív, különösen személyes adatokat is tartalmazó kutatásnál különös odafigyeléssel kell figyelembe venni a kiválasztott adatrepozitórium vagy adattár felhasználási feltételeiben leírtakat
- A legtöbb esetben csak olyan kutatási adatok repozitálhatók, amelyek nem tartalmaznak szenzitív, különösen személyes adatot, vagy más, személyek beazonosítására alkalmas információt
- Kivételt jelenthet, ha:
- valamennyi érintett személy (pl. a kutatás finanszírozója, kutatásvezetője és valamennyi, személyes/érzékeny adattal érintett alanya) kifejezett írásos beleegyezését adta a személyes/érzékeny adatok tárolásához és nyilvánosságra hozatalához, és a feltöltő ezek birtokában, valamint a megfelelő hozzáférési szintek beállításával helyezi el azokat
- valamennyi azonosított vagy azonosítható személy elhunyt, és nincs olyan körülmény vagy jogszabály, amely kifejezetten korlátozná a személyes adatok vagy információk kiadását
- a személyes/érzékeny adatokat is tartalmazó kutatási adatokhoz történő repozitóriumi hozzáférés engedélyköteles (a feltöltő szándékának és jogosultságának megfelelő beállításokkal) és az engedélykérés a rendszerben megoldott
Mesterséges intelligencia a kutatásban
Tudományterületfüggő, hogy milyen mértékben, de általános tendencia, hogy egyre több kutatásban használnak valamilyen módon mesterséges intelligenciát, mesterséges intelligencia alapú algoritmust, mesterséges intelligencia által támogatott kutatási eszközöket. Mesterséges intelligencia segítségével készült adat, adatelemzés, szöveg, tanulmány vagy egyéb kutatási anyag esetében fel kell tüntetni az alkalmazott módszert és eszközt, illetve megfelelő (visszakereshető) módon hivatkozni kell rá.
- A kutatás előkészítése során:
- A kutatási adatok kezelésének költségei
-
Már a kutatás tervezésekor figyelmet kell fordítani a kutatási adatokhoz kapcsolódó költségek kalkulálására, illetve a finanszírozás megtervezésére, annak a kutatás költségeibe való beépítésére.
Ilyen költségek lehetnek például:
- a kutatás alatti adattárolás felmerülő költségei (pl. fizikai vagy digitális tárolók, fizetős felhőszolgáltatások költségei)
- a kutatás lezárulta után az adatok archiválásra való előkészítésének költségei (pl. adatrendezés, adattisztítás költségei)
- a személyes, szenzitív vagy bizalmas adatok miatti anonimizálás vagy egyéb eljárás költségei
- a kutatási adatok hosszú távú megőrzésének és megosztásának költségei (pl. kutatási honlap létrehozásának és fenntartásának díja, repozitóriumi szolgáltatás díja)
- a kutatási adatok FAIR módon való megosztásának költségei (pl. adatgazdász segítségének díja, perzisztens azonosító költsége)
A ténylegesen kifizetendő költségek nagymértékben függhetnek a kutató vagy kutatás befogadó intézményétől, illetve annak ingyenesen biztosított szolgáltatásainak körétől. A kutatás tervezésekor érdemes körültekintően tájékozódni az igénybevehető, térítésmentesen rendelkezésre álló lehetőségekről, támogatási formákról.
A kutatási adatokkal kapcsolatban felmerülő költségek tervezésében és kiszámolásában segítséget nyújthat a UK Data Service Data management costing tool and checklist lehetősége.
- Kutatási adatokkal kapcsolatos fogalmak, meghatározások
-
Kutatási adatokkal és kutatásiadat-kezeléssel kapcsolatos fontos fogalmak és definíciók találhatóak az Adatrepozitórium Platform oldal Fogalomtár aloldalán, valamint a Framework for Open and Reproducible Research Training oldal jegyzékében.
- Adatrepozitóriumok használatával kapcsolatos ismeretek terjesztése, kutatásiadat-kezelési tanácsadás a HUN-REN ARP-projektben
-
A repozitóriumi infrastruktúra kialakítása mellett a HUN-REN Adatrepozitórium Platform projekt kiemelt feladata az adatrepozitóriumok használatával kapcsolatos ismeretek terjesztése, a szükséges HUN-REN- és intézményi szintű adatkezelési irányelvek és szabályozások létrehozása vagy annak támogatása, valamint a hazai és nemzetközi adat- és metaadat-kezelési, -tárolási szabványok és ajánlások, jógyakorlatok meghonosítása, ezzel is lehetővé téve a FAIR adatrepozitórium-kultúra megteremtését a HUN-REN intézményhálózatán belül.
Ennek érdekében
- A HUN-REN ARP honlapján folyamatosan frissülő ismeretanyag olvasható a kutatási adatokkal és azok kezelésével kapcsolatban
- A honlapon és különböző kommunikációs csatornákon keresztül folyamatos tájékoztatást kapnak a kutatók a közelgő rendezvényekről, eseményekről
- A HUN-REN ARP szakértői rendszeresen tartanak előadásokat, képzéseket, a korábbi események felvételei megtekinthetők a HUN-REN ARP oldalán
- A HUN-REN ARP Nagykövet Program keretében elkezdődött az intézményi adatgazdász hálózat kialakításának megalapozása, az intézményi jógyakorlatok kialakítása
- A HUN-REN ARP munkatársai rendelkezésre állnak bármilyen, a témával kapcsolatos kérdésben, probléma megoldásában
A HUN-REN kutatói információkat szerezhetnek a HUN-REN ARP Portálról, valamint az ARP szakembereitől. Az ARP szakemberei készséggel állnak rendelkezésre konzultációs lehetőséggel és támogatás nyújtásával a kutatás bármely szakaszában az adatkezeléssel és a repozitóriumhasználattal kapcsolatban felmerülő kérdések megválaszolására a support@researchdata.hu email címen.